Google DeepMind has unveiled CAT3D, a groundbreaking generative AI model capable of creating high-quality, three-dimensional models from a single 2D image. Announced via a research paper and demonstration, the technology represents a significant leap forward in AI-driven content creation, promising to simplify and accelerate workflows for developers, designers, and artists.
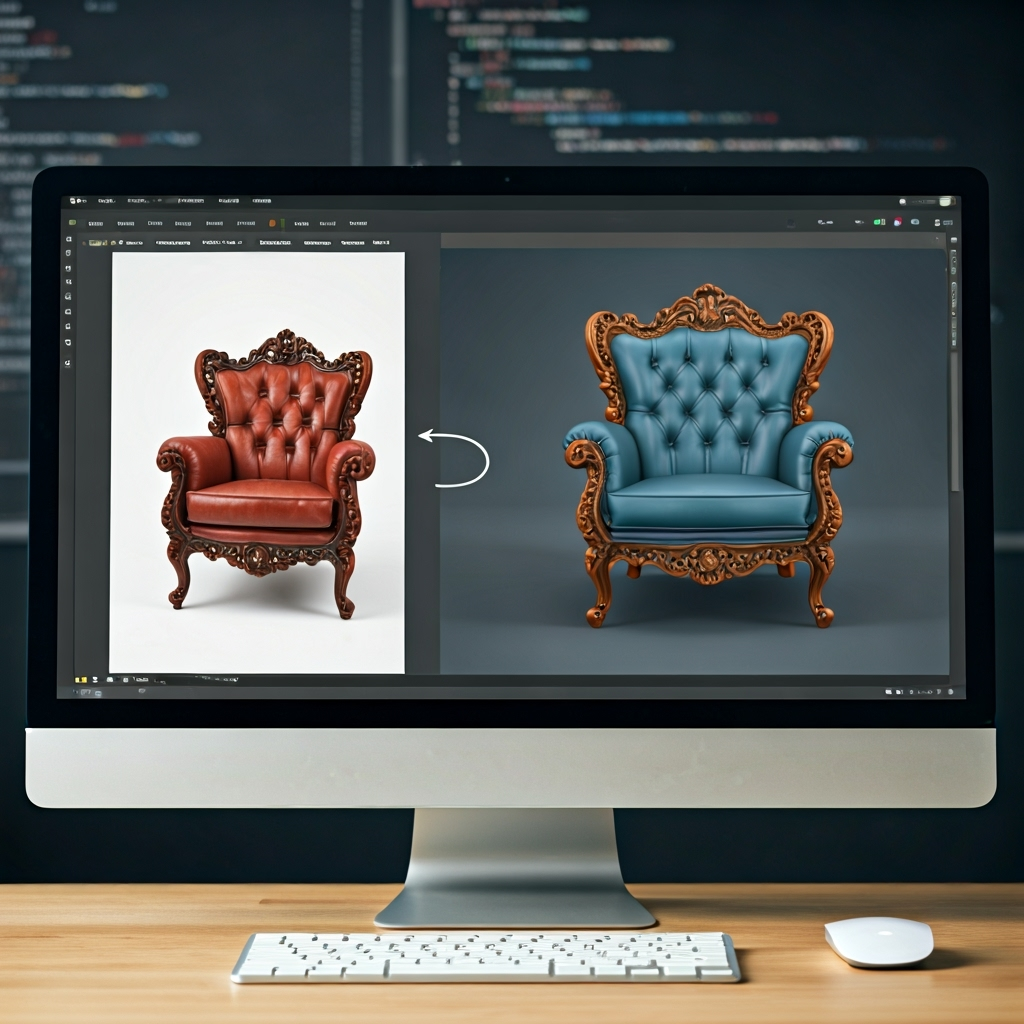
Unlike traditional methods like photogrammetry, which require multiple images from various angles to construct a 3D object, CAT3D (Context-Aware Transformers for 3D) uses a novel diffusion-based approach. The model was trained on a massive dataset of images and their corresponding 3D shapes, allowing it to infer an object’s complete geometry from a single viewpoint. It can generate not only the visible parts of an object but also plausibly synthesizes the unseen sides, creating a complete and coherent 3D mesh.
In demonstrations, CAT3D produced impressive results in seconds, converting photographs of everything from household items to complex architectural elements into detailed 3D assets. The model is also capable of generating multiple variations from the same input image, giving creators a range of options to choose from.
The implications for industries like gaming, augmented reality (AR), e-commerce, and industrial design are profound. Game developers could rapidly populate virtual worlds with unique assets, while online retailers could offer interactive 3D previews of their products. This innovation positions Google as a key player in the emerging field of 3D generative AI, competing with specialized startups like Luma AI and established firms investing in similar research. While not yet available as a public-facing tool, CAT3D signals Google’s intent to build a comprehensive ecosystem of creative AI tools beyond text and image generation.